



基于Higress构建企业级AI网关的Token管控最佳实践
发布时间 2025-03-03
一、 场景驱动:为什么企业需要AI网关?
随着如DeepSeek等大模型的火热,大模型技术发展重心正从训练向推理阶段加速迁移,越来越多的公司已经开始设计符满足企业内部需求和外部商业方向的大模型应用,并在生产环境中进行部署。在大模型应用规模化落地的背景下,企业面临三大核心挑战:
- Token成本管控:LLM服务按Token计费模式下的预算控制
- 资源公平分配:多租户场景下的资源配额管理
- 服务稳定性保障:突发流量下的服务降级与熔断
Higress AI网关通过三大核心能力解决上述问题:
- 细粒度Token计量:精确统计输入/输出Token消耗
- 动态配额管理:支持实时调整租户配额
- 分级限流策略:分钟级调用次数与Token消耗双重控制
二、快速入门:五分钟搭建管控体系
一键式环境部署
curl -sS https://higress.cn/ai-gateway/install.sh | bash生产环境建议采用K8s部署或云上部署方式(参考Higress部署指南),支持自动扩缩容与滚动升级。
可视化控制台配置
访问 http://localhost:8001 完成初始化:
- 供应商管理:创建不同模型供应商的API密钥
- 消费者管理:创建分级账号体系,配置不同的消费者权限
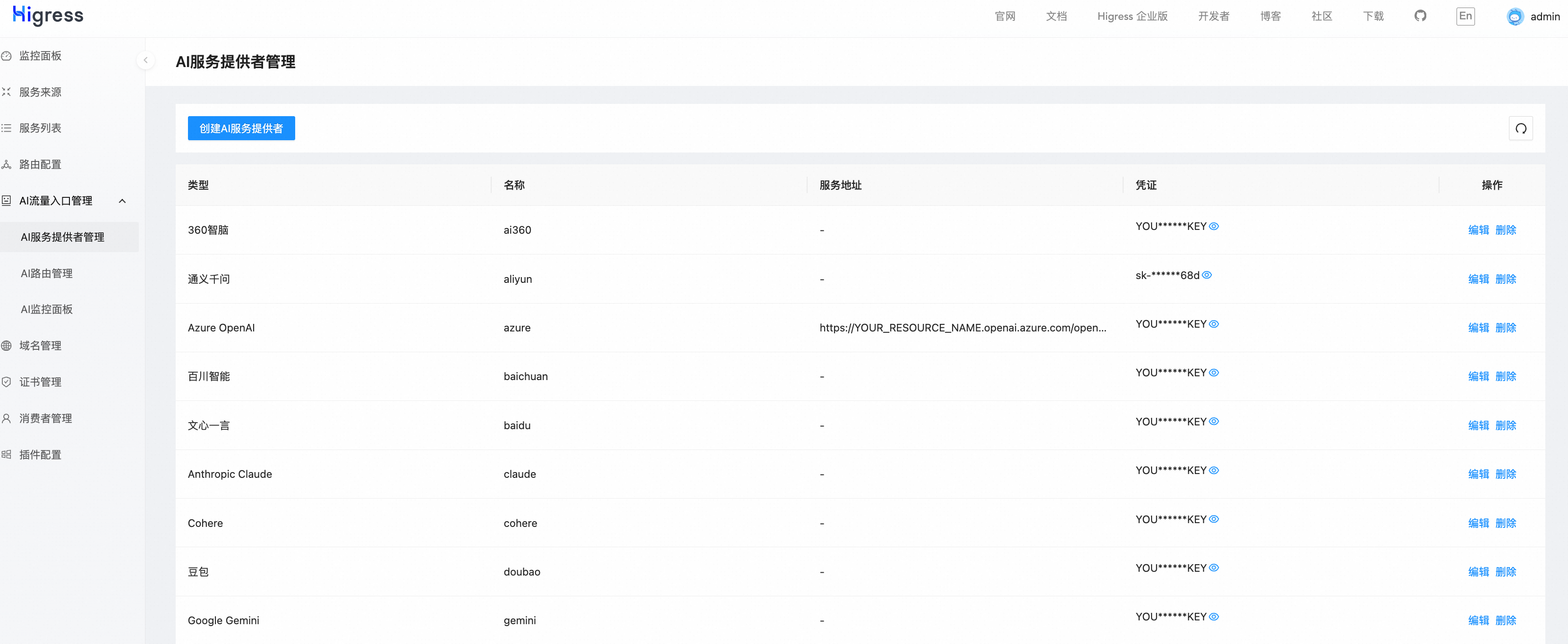
分级配额管理
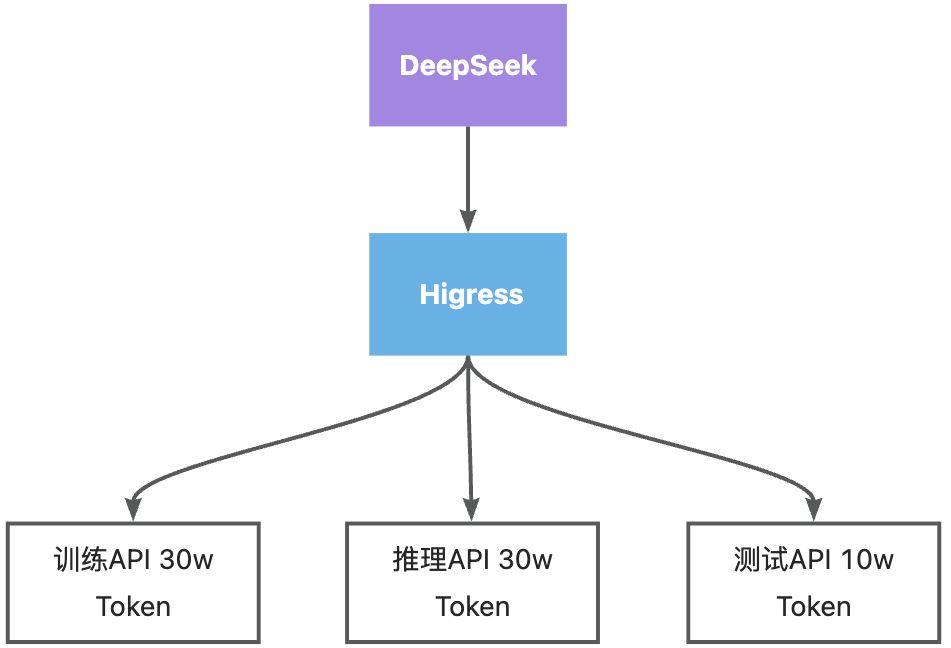
Higress支持对不同的AI路由进行不同的配额策略管理,管理员可通过URL形式进行动态的路由管理调配。
#为特定消费者增加固定数量配额curl 'http://localhost:8080/v1/chat/completions/quota/delta' -d 'consumer=aliyun-user1&value=100'针对某一模型的不同场景,不同的配额数量可以让企业成本进一步优化。
同时,也可以直接为特定的API-KEY配置秒级/分钟级/小时级的Token数量限制,防止因突发流量或API-KEY泄露导致的费用突增。
rule_items:- limit_by_per_header: "x-api-key" limit_keys: - key: "sk-XXXXXXXXX" token_per_minute: 100000rule_name: "default_rule"四、可观测性:数据驱动的决策体系
多维监控看板
Higress内置多个观测维度,支持自定义指标接入Prometheus,也接入了Grafana看板,管理员在观测界面可以实时获取当前AI API数据。AI场景下内置的指标有:
- 供应商健康状态
- 模型使用量分布
- 消费者使用量观测
- Token消耗趋势
预警规则配置
针对Token异常数量、流量异常增长的情况,在控制台侧观测界面可以配置告警信息。触发告警时,运维工程师可以及时介入,避免资金损失。
