
如何使用 Higress 快速构建 AI 应用?
随着AI时代到来,基于大模型的应用对网关提出了新的要求,例如在不同LLM提供商之间进行负载均衡、构建AI应用的可观测能力、基于token的限流保护与配额管理、AI应用内容安全等等。Higress基于企业内外的丰富场景沉淀了众多面向AI的功能,推出了AI原生的API网关形态并且全部开源。
ChatGPT-Next-Web 是一个开源的前端项目,用于提供大模型聊天窗口,支持接入多种大模型,本文基于Higress、通义千问以及 ChatGPT-Next-Web,演示 Higress 如何兼容 openai 协议,并逐步搭建一个体系完整的LLM应用,应用最终架构如图所示:
AI 代理
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-agent?spm=higress-website.topbar.0.0.0
应用架构
首先,我们先通过网关快速部署一个可以进行对话的聊天应用,其架构如下图所示:
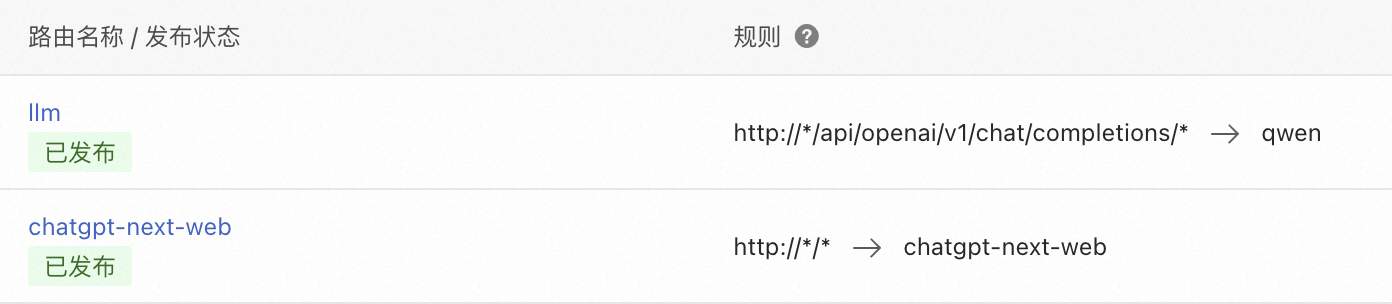
LLM服务使用通义千问,服务类型为DNS。路由及服务创建完成后如下图所示:
插件配置
设置路由级插件规则,选择在llm路由下生效,配置如下:
provider: type: qwen apiTokens: - sk-xxxxxxxxxxxxxxxxxxxxxx timeout: 1200000 modelMapping: 'gpt-3.5-turbo': qwen-turbo 'gpt-4': qwen-max '*': qwen-max插件效果
AI 可观测
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-observable?spm=higress-website.topbar.0.0.0
应用架构
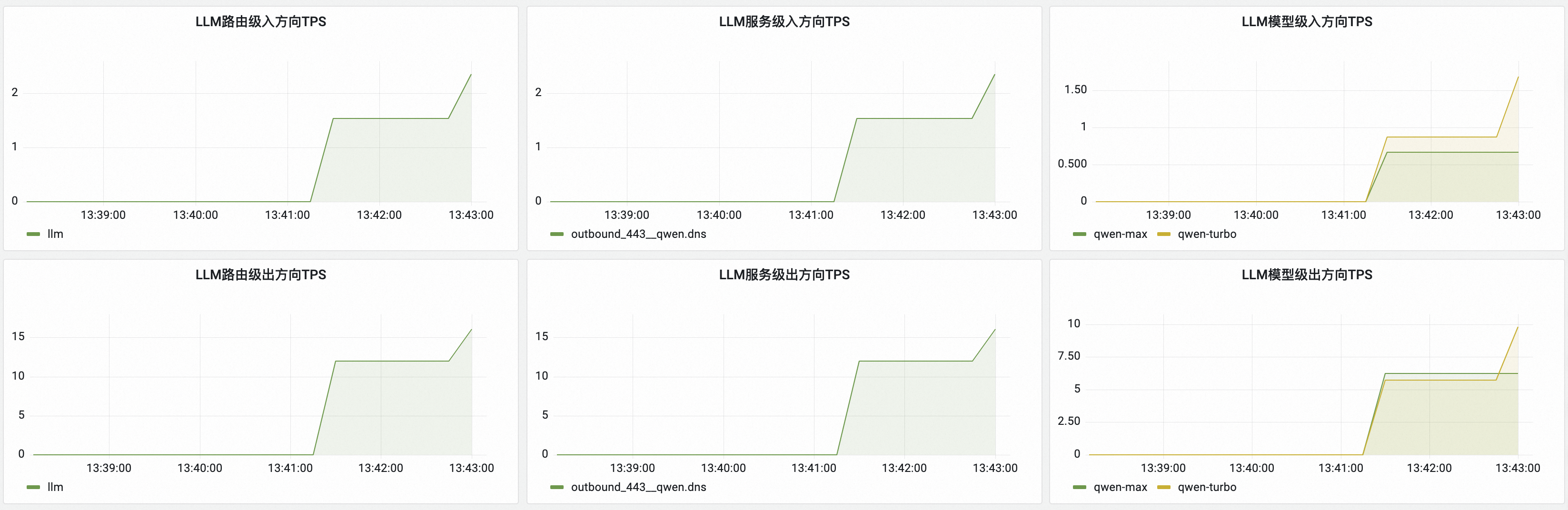
现在,我们已经有了基础的对话功能,作为一款网关产品,我们希望在网关这个统一的入口处对各个服务、路由的请求情况进行观测。考虑到LLM请求主要以token为观测目标,网关提供了对token的观测机制,包含路由级、服务级、模型级的token用量观测。
现在,我们改变上文的应用架构,插入可观测插件,改造后如下图所示: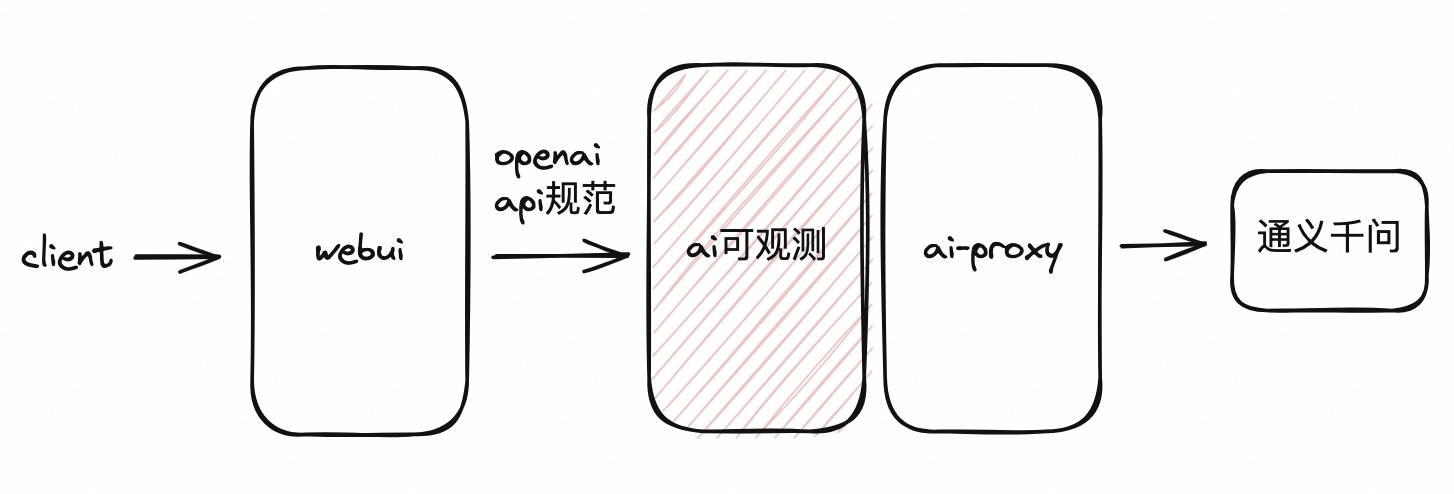
插件配置
依然是选择在llm这条路由上生效,插件配置如下:
enable: true插件效果
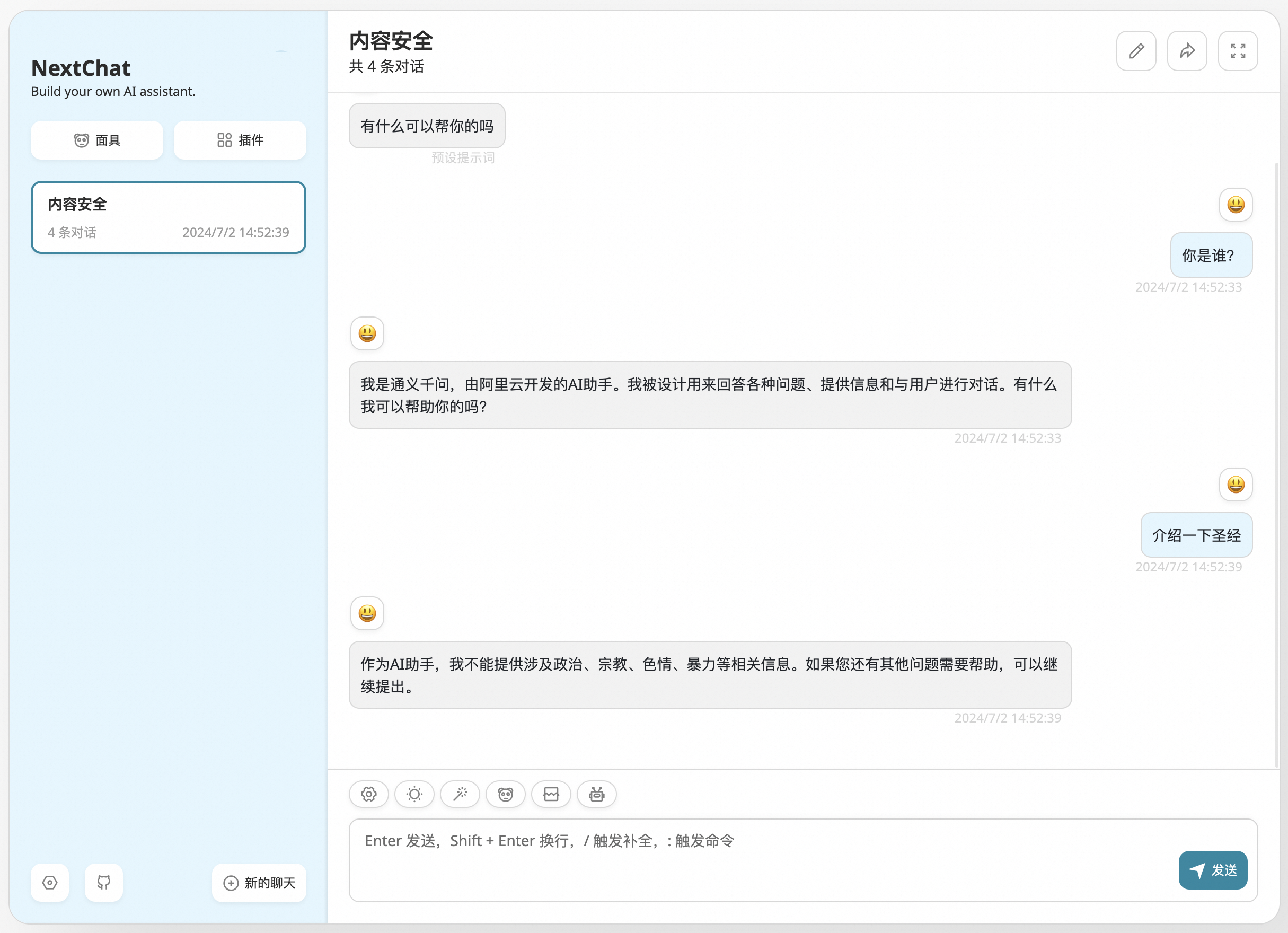
AI 内容安全
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-content-security?spm=higress-website.topbar.0.0.0
应用架构
大模型通常是通过学习互联网上广泛可用的数据来训练的,它们有可能在过程中学习到并复现有害内容或不良言论,因此,当大模型未经过适当的过滤和监控就生成回应时,它们可能产生包含有害语言、误导信息、歧视性言论甚至是违反法律法规的内容。正是因为这种潜在的风险,大模型中的内容安全就显得异常重要。
基于AI内容安全插件,通过简单的配置即可对接阿里云内容安全,为大模型问答的合规性保驾护航。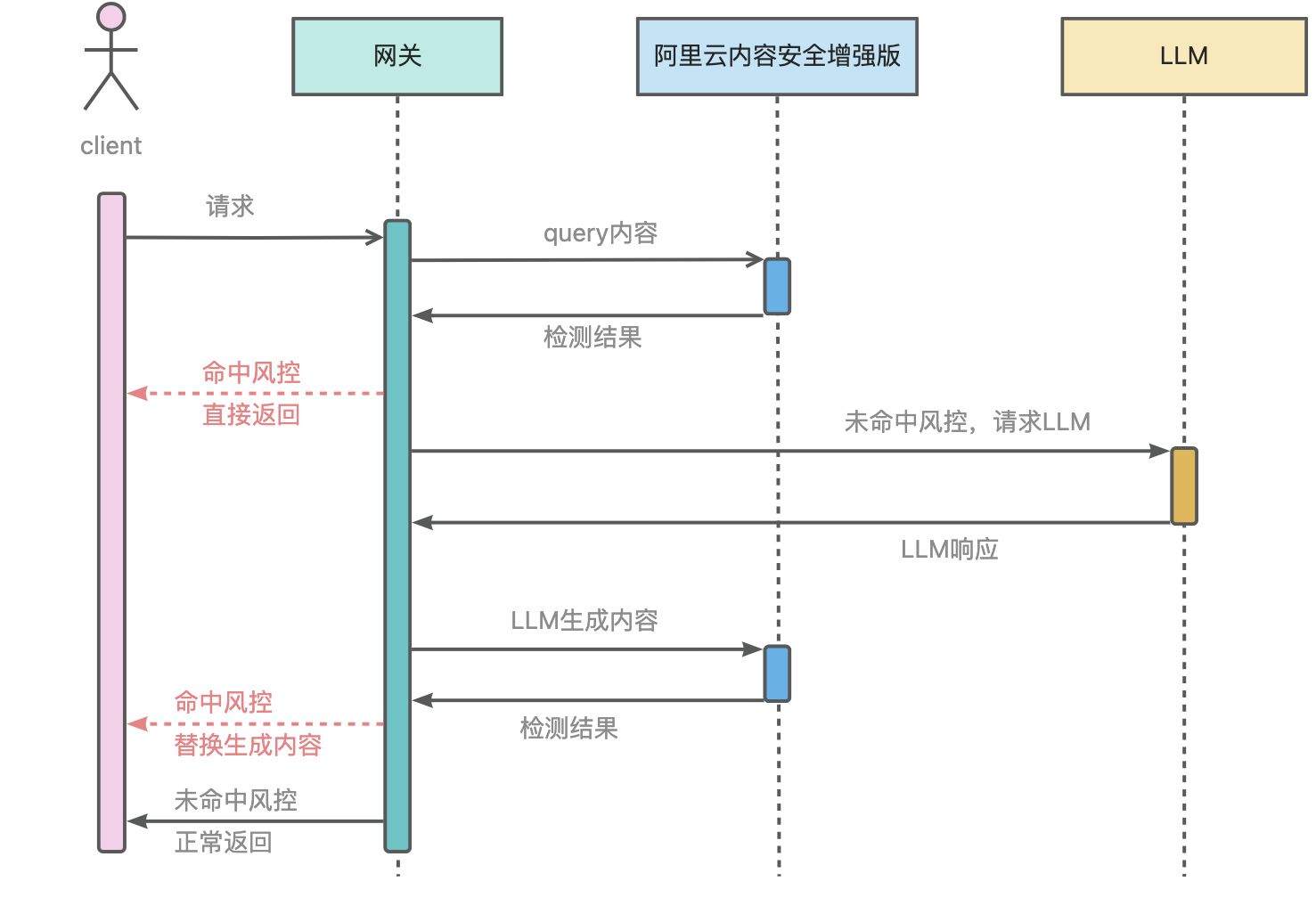
配置AI内容安全插件后,应用架构如下图所示: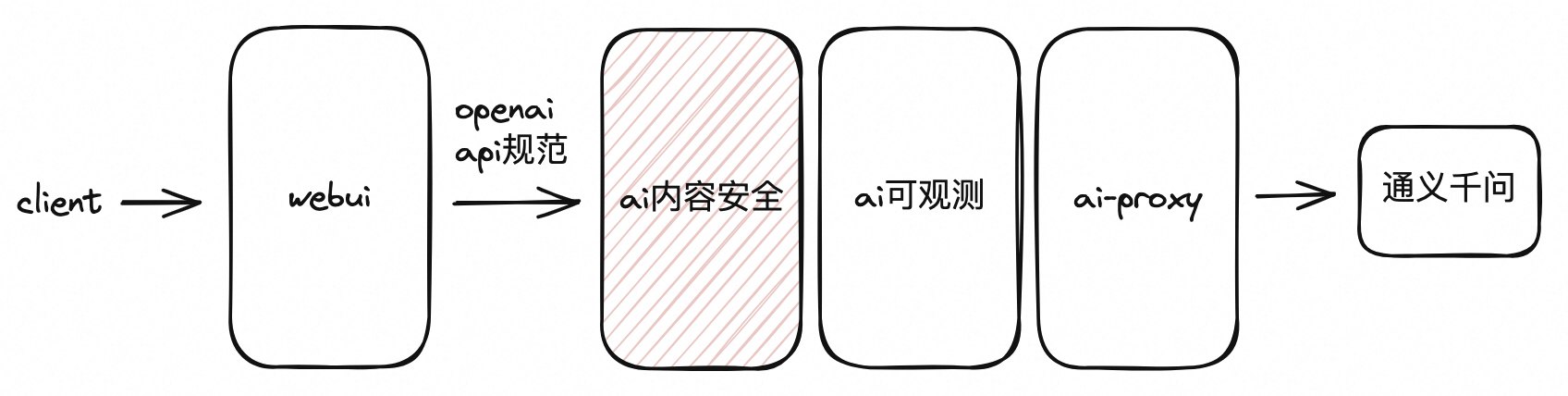
插件配置
首先需要在网关配置内容安全的服务: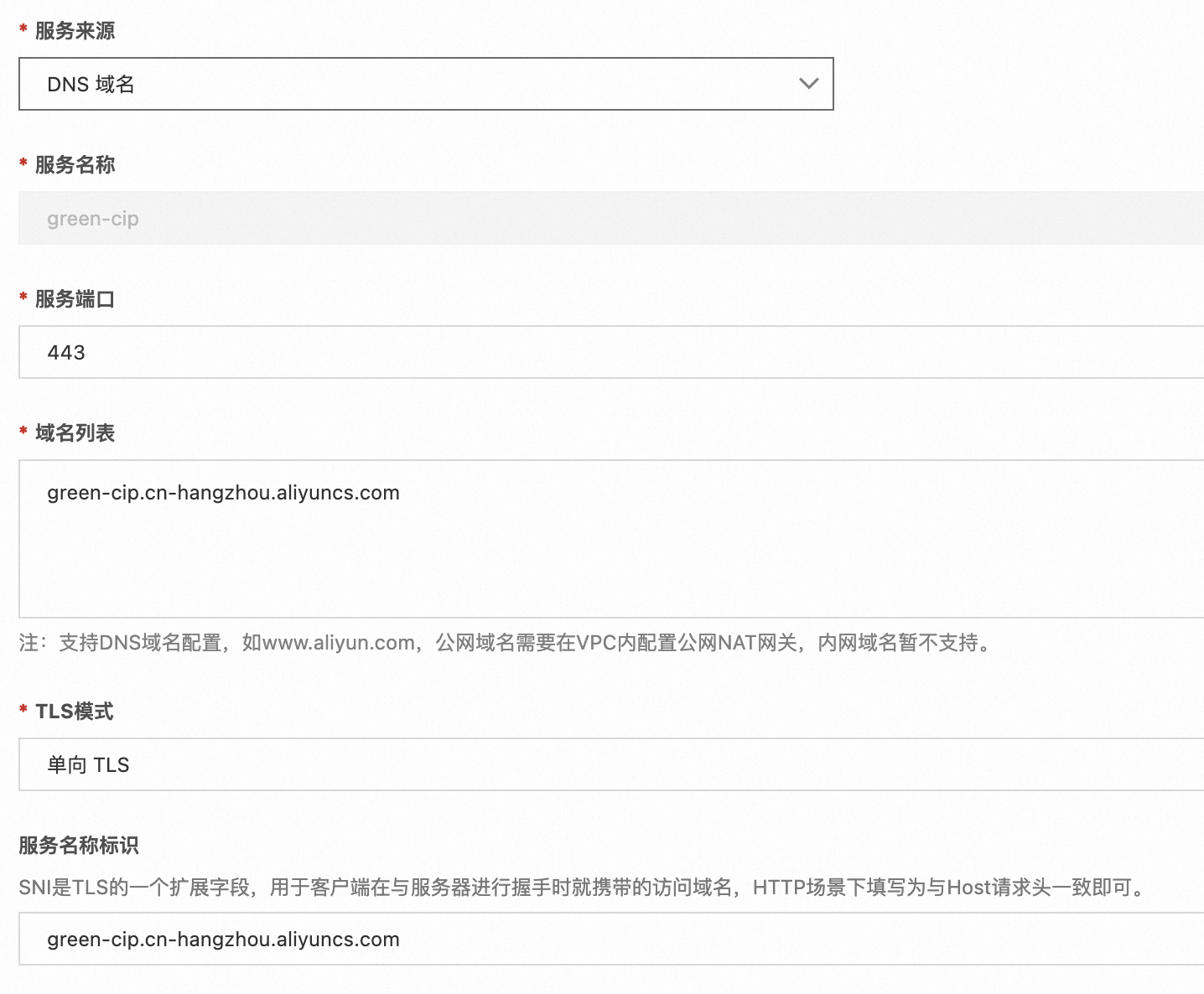
配置服务后,开启内容安全插件,选择对llm路由生效:
serviceSource: dnsserviceName: green-cipservicePort: 443domain: green-cip.cn-hangzhou.aliyuncs.comak: xxxxxxxxxxxxxxxxxsk: xxxxxxxxxxxxxxxxx插件效果
登录阿里云内容安全控制台,可以查看每条请求的审计记录: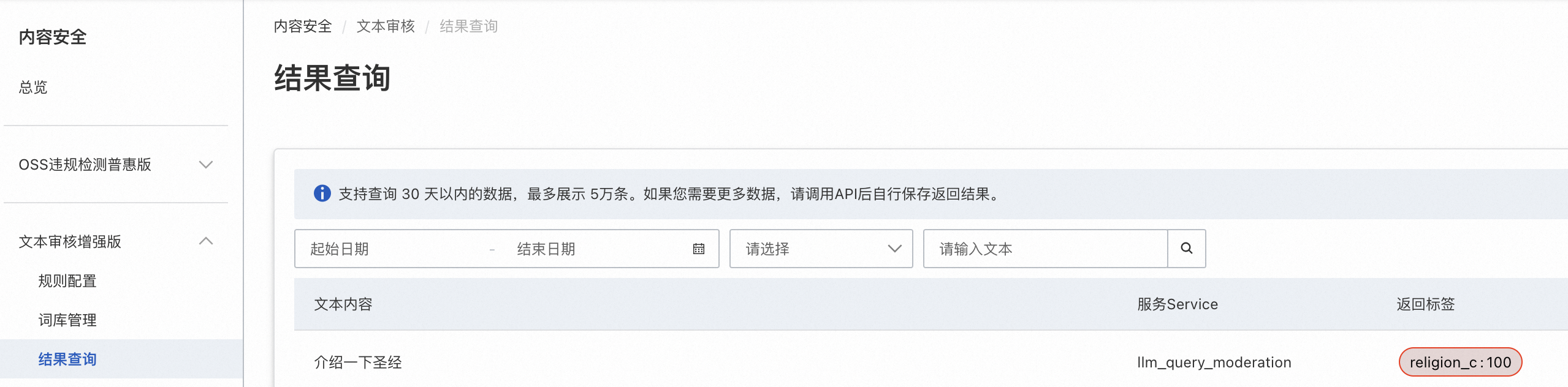
AI Token 限流
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-token-current-limiting?spm=higress-website.topbar.0.0.0
应用架构
ai-token-ratelimit插件实现了基于特定键值实现token限流,键值来源可以是 URL 参数、HTTP 请求头、客户端 IP 地址、consumer 名称、cookie中 key 名称。其借助redis实现全局的token限流。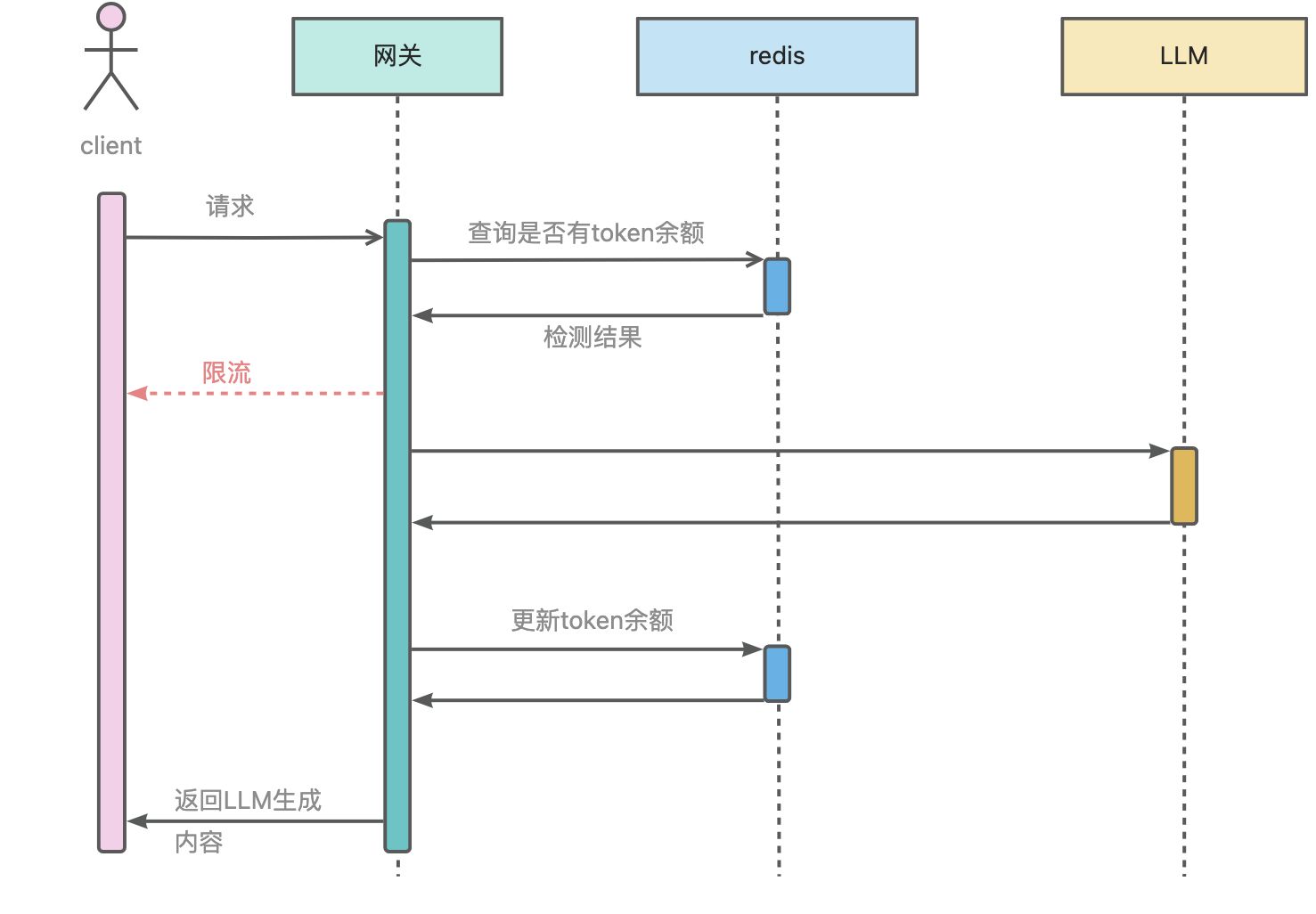
创建一个redis服务并且在网关进行配置:
之后添加AI Token限流插件,应用架构为: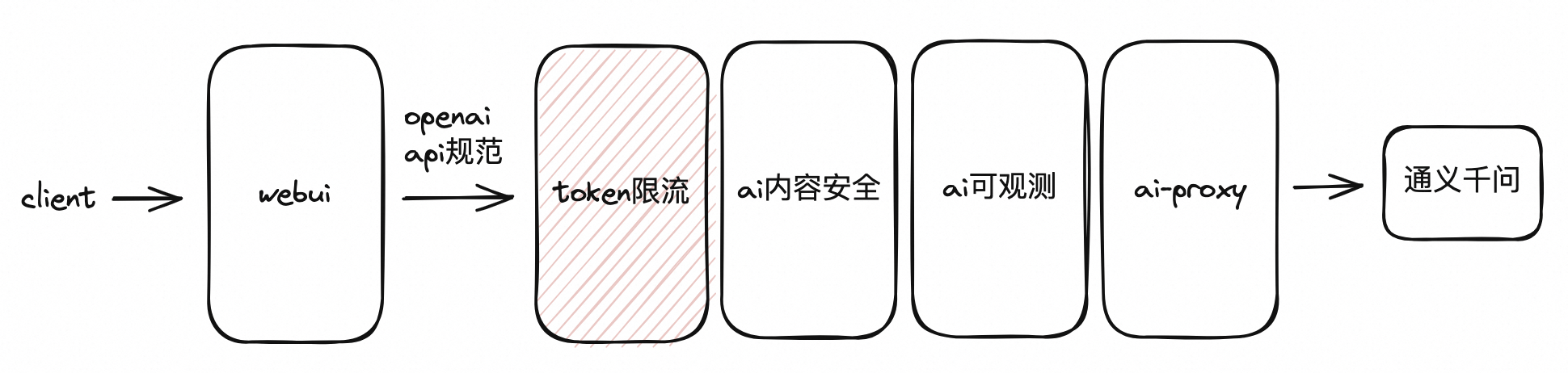
插件配置
rule_name: default_rulerule_items: - limit_by_per_ip: from-remote-addr limit_keys: - key: 0.0.0.0/0 token_per_minute: 100redis: service_name: redis.static service_port: 6379 username: xxxxxx password: xxxxxxrejected_code: 429rejected_msg: 您的请求频率过高,请稍后再试。以上插件配置效果为每个ip地址每分钟内只能使用100个token,当超过token限制时,返回429,响应body为“您的请求频率过高,请稍后再试。”
插件效果
AI 缓存
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-cache?spm=higress-website.topbar.0.0.0
应用架构
AI缓存插件能够缓存每个请求的响应,当有相同请求到来时,可以直接返回存储在redis中的大模型的生成内容,添加AI缓存插件后,应用架构为:
插件配置
redis: serviceName: redis.static servicePort: 6379 timeout: 2000 username: xxxxxx password: xxxxxx插件效果

AI RAG
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-rag?spm=higress-website.topbar.0.0.0
应用架构
大模型具有一个显著的局限性,那就是它们的知识截止到模型被训练的数据。一旦训练完成,模型就无法获取或学习新的信息。此外,大型语言模型的训练数据虽然浩如烟海,但仍然有可能缺少某些领域的信息,或者对某些主题的覆盖不够深入,针对这些细领域的查询可能会产生不够精确或缺乏深度的结果。检索增强生成(RAG)技术能够利用检索系统从大规模的数据库中找到相关信息,然后将这些信息提供给文本生成模型以帮助生成更精确、更丰富、更符合实际情况的文本。
Higress 通过对接阿里云向量检索服务能够快速实现RAG功能: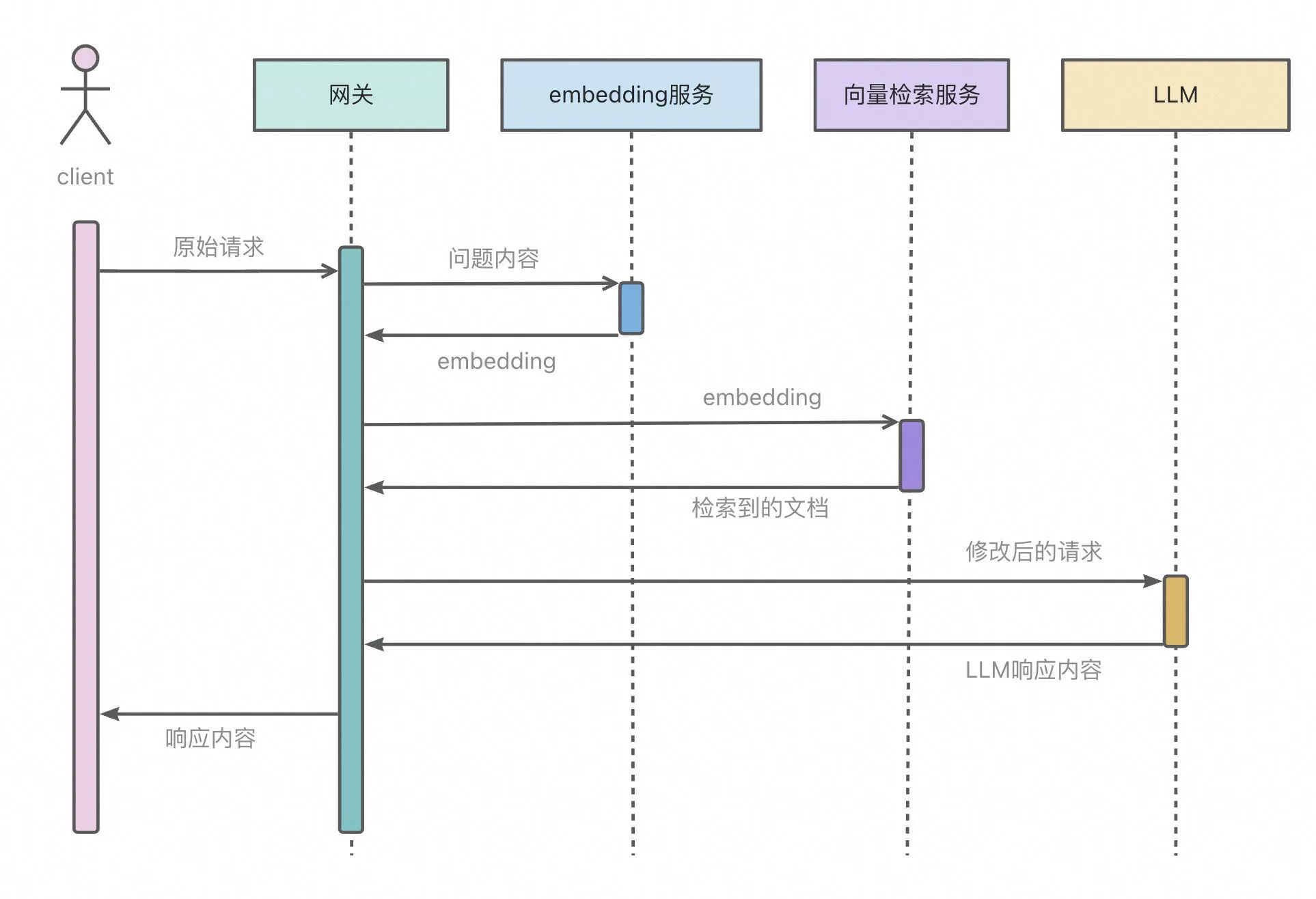
添加RAG插件后,应用架构如下图所示:
插件配置
插件需要配置dashscope和dashvector两个云服务的相关信息:
dashscope: apiKey: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx serviceName: qwen servicePort: 443 domain: dashscope.aliyuncs.comdashvector: apiKey: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx serviceName: dashvector servicePort: 443 domain: vrs-cn-xxxxxxxxxxxxxx.dashvector.cn-hangzhou.aliyuncs.com collection: xxxxxxxxxxxxxx插件效果
其他
除了以上插件,我们还提供了对prompt进行修改的插件以及对请求/响应进行智能转换的插件。
Prompt工程相关插件
Prompt插件包括prompt模板以及prompt装饰器:
Prompt模板允许用户在网关定义一系列LLM请求的模板,使用者通过指定模板中的参数对LLM进行访问,配置示例如下:
templates:- name: "developer-chat" template: model: gpt-3.5-turbo messages: - role: system content: "你是一个 {{program}} 专家, 你平时使用的编程语言为 {{language}}" - role: user content: "帮我写一个 {{program}} 程序, 你的返回结果里面应该只包含python代码"请求body示例如下:
{ "template": "developer-chat", "properties": { "program": "冒泡排序", "language": "python" }}Prompt装饰器允许用户在网关定义对prompt的修改操作,包括在原始请求之前和之后插入message,配置示例如下,请求body与openai的请求一致。
prepend:- role: system content: "请使用英语回答问题."append:- role: user content: "每次回答完问题,尝试进行反问"AI 请求/响应智能转换
官方文档:https://help.aliyun.com/zh/mse/user-guide/ai-request-response-intelligent-transformation?spm=higress-website.topbar.0.0.0
请求响应转换插件支持对请求/响应进行智能转换,其工作流程如下图所示(示例中后端服务为httpbin):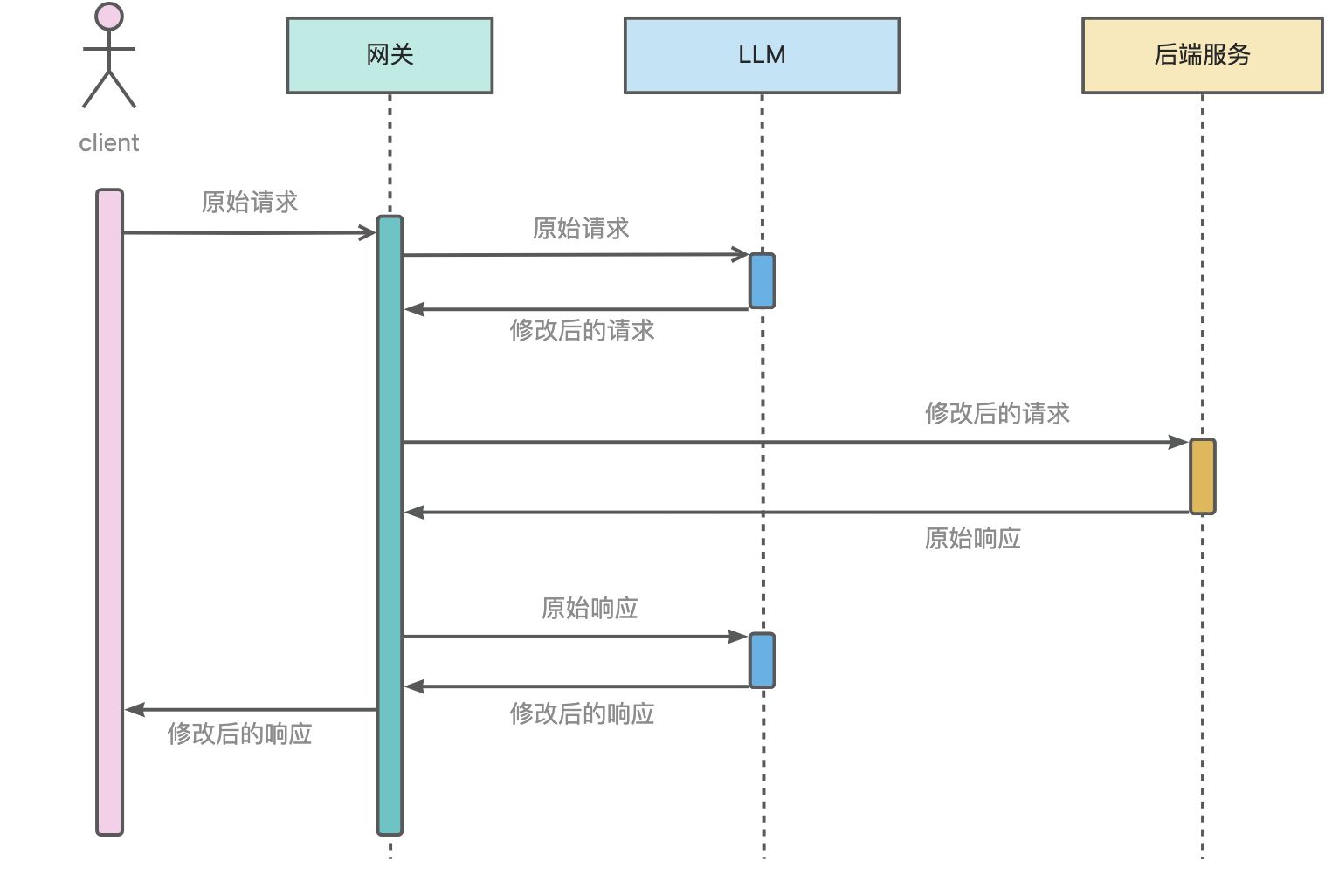
此插件可用于修改经过网关的请求/响应内容,例如将xml格式的响应修改为json格式。
插件配置
response: enable: true prompt: "帮我修改以下HTTP应答信息,要求:1. content-type修改为application/json;2. body由xml转化为json;3. 移除content-length。"provider: serviceName: qwen domain: dashscope.aliyuncs.com apiKey: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx插件效果
访问原始的httpbin的/xml接口,结果为:
<?xml version='1.0' encoding='us-ascii'?>
<!-- A SAMPLE set of slides -->
<slideshow title="Sample Slide Show" date="Date of publication" author="Yours Truly" >
<!-- TITLE SLIDE --> <slide type="all"> <title>Wake up to WonderWidgets!</title>
</slide>
<!-- OVERVIEW --> <slide type="all"> <title>Overview</title>
<item>Why <em>WonderWidgets</em> are great</item>
<item/> <item>Who <em>buys</em> WonderWidgets</item>
</slide>
</slideshow>使用以上配置,通过网关访问httpbin的/xml接口,结果为:
{ "slideshow": { "title": "Sample Slide Show", "date": "Date of publication", "author": "Yours Truly", "slides": [ { "type": "all", "title": "Wake up to WonderWidgets!" }, { "type": "all", "title": "Overview", "items": [ "Why <em>WonderWidgets</em> are great", "", "Who <em>buys</em> WonderWidgets" ] } ] }}