
评估工程正成为下一轮 Agent 演进的重点
作者:马云雷&望宸
一、导读
在传统软件工程中,测试是保障质量与稳定性的核心环节。它验证系统的确定性逻辑:基于预设的规则,验证输入的可靠性。而 AI 系统的核心能力不再是执行预设的规则,而是基于概率模型进行推理和生成。结果的不确定性、语义的多义性、以及上下文的敏感性,使得原有测试方法难以刻画模型行为。这一转变,促使评估工程成为下一轮 Agent 演进的重点。
评估工程,贯穿整个 AI 生命周期,它的目标是定义、采集并量化 Agent 的表现质量,涵盖输出正确度、可解释性、偏好一致性与安全性。从架构角度看,评估工程是 AI 工程体系中最靠近“人类判断”的一环,既涉及指标体系的定义,又包含算法层的建模与反馈机制。随着 SFT(监督微调)、RLHF(基于人类反馈的强化学习)、LLM-as-a-Judge(模型裁决评估)以及 Reward Model(奖励模型)等技术或范式逐渐成熟,评估工程正从经验驱动走向体系化、工程化和自动化。
阿里云 CIO 蒋林泉曾分享过:在落地大模型技术过程中总结过一套方法论,叫 RIDE,即 Reorganize(重组组织与生产关系)、Identify(识别业务痛点与 AI 机会)、Define(定义指标与运营体系)、和 Execute(推进数据建设与工程落地)。其中,Execute 中提到了评估工程重要性的核心原因,即这一轮大模型最关键的区别在于:度量数据和评测均没有标准的范式。这就意味着,这既是提升产品力的难点,同时也是产品竞争力的护城河。
在 AI 领域里经常提到一个词叫“品味”,这里讲的“品味”,其实就是如何设计评估工程,即对 Agent 的输出进行评价。如果没有评估,就很难理解不同的模型会如何影响我们的用例。
二、从确定性到不确定性
在传统的软件工程中,测试覆盖率和准确率是评价质量的指标。传统软件工程的测试体系建立在三个假设上:
- 系统状态是可预测且有限的。
- 故障是离散的、可复现的。
- 测试集可以覆盖主要路径,从而保证回归稳定性。
这些假设使测试活动可以高度自动化:编写单元测试、执行、检测结果是否匹配。测试的目标是消灭 bug。在这种逻辑下,质量的度量接近“零缺陷工程”,并且保障可重复性与向前兼容性。
AI 系统的不确定性,源自三个方面:
- 模型架构的不确定性:Transformer 等生成模型通过概率分布预测下一个 token,本身就是多解问题的生成器。
- 数据驱动的不完全性:模型的世界认知取决于训练数据的分布,一旦语境超出训练覆盖范围,输出结果就会失去稳定性。
- 交互环境的开放性:用户输入多样、上下文动态变化,任务目标模糊或多义。
这使得 AI 系统的故障模式不同于 bug。它是一种漂移,表现为输出分布的偏移、语义理解的失准、或行为策略的不一致。因此,对 Agent 而言,评估不再仅仅是部署前的一个阶段,而是由后训练、持续监控、自动化评估与治理,所构成的评估工程。
三、用魔法打败魔法
评估工程经历了从规则匹配、语义匹配、模型评估的演进过程,每个阶段都是对“什么是更好的答案”这一核心问题的重新定义。
阶段一:规则匹配
在自然语言处理早期,评估主要基于规则化的重合度指标。典型代表是机器翻译的 BLEU(Bilingual Evaluation Understudy) 和用于文本摘要的 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。它们的核心思路是通过比较模型输出与人工参考答案的重合程度来计分,从而度量生成结果的“接近度”。
但这种方法对于评估需要捕捉语义、风格、语气和创造力等细微差别的现代生成式 AI 模型来说,存在根本性的不足。一个模型生成的文本可能在措辞上与参考答案完全不同,但在语义上却更准确、更具洞察力。BLEU、ROUGE无法识别这种情况,甚至可能给予低分。
阶段二:语义匹配
当模型具备语义理解能力后,评估进入语义层次。BERTScore(基于 BERT 表示的文本生成质量评估指标) 和 COMET(跨语言优化的翻译质量评估指标)等方法引入了向量空间语义匹配。通过计算生成文本与参考答案在嵌入空间中的余弦相似度,评估输出的语义接近度。这使得模型可以被奖励为生成不同但合理的答案。
例如:
参考答案:“猫坐在垫子上。”
模型输出:“垫子上有一只猫。”
在语义匹配指标下,这种输出会得到高分,而不是被视为错误。但这一阶段的评估仍有两个局限:
- 仍需参考答案:难以适用于开放式的生成或对话;
- 无法表达偏好:无法判断哪种答案更自然、更符合用户习惯。
语义指标的价值在于:它让我们开始从答案正确性转向语义合理性,但仍然没触及行为一致性这一核心问题。
阶段三:模型评估
随着大模型迈过拐点,评估方法进入第三阶段,LLM-as-a-Judge,其核心思想是让模型学习人类的主观偏好,即利用一个功能强大的大型语言模型(通常是前沿模型)来扮演裁判的角色,对另一个 AI 模型(或应用)的输出进行评分、排序或选择,即用魔法打败魔法。
-
工作机制:向裁判 LLM 提供一个精心设计的提示词。这个提示通常包含:
- 被评估模型的输出。
- 产生该输出的原始输入或问题。
- 一套明确的评估标准或“评分指南”,用自然语言描述,例如“请评估以下回答的帮助性、事实准确性和礼貌程度”。裁判 LLM 随后会根据这些信息,生成一个分数、一个判断(如回答 A 优于回答 B)或一段详细的评估反馈。
-
核心应用场景:
- 数据标注:大规模、低成本地为数据集进行标注,合成检测数据,用于监督式微调或创建新的评估基准。
- 实时验证:在应用中充当护栏,在输出返回给最终用户之前,实时检查其是否存在幻觉、违反政策或包含有害内容。
- 为模型优化提供反馈:生成详细、可解释的反馈,指导模型的迭代改进。例如,其中一个 LLM 根据一套伦理原则来评估和修正另一个 LLM 的输出,从而实现模型的自我完善。
从一个更深层次的视角来看,LLM-as-a-Judge 范式能够将高级的、主观的人类偏好(通过自然语言评分指南表达)编译成一个可扩展、自动化且可重复执行的评估函数。这个过程将原本属于定性评估的艺术,转变为一门可以系统化实施的工程学科。其逻辑在于,该范式接收了抽象的、定性的输入(如评估回答的创造力),并将其转化为结构化的、定量的输出(如一个1到5的分数)。这种转化过程使得那些以往只能依赖昂贵且缓慢的人工评估才能衡量的复杂、主观标准,现在可以通过工程化的方式进行系统性评估。
无论是 SFT(监督微调),还是RLHF(基于人类反馈的强化学习),LLM-as-a-Judge 都是一个更高效的对齐人类偏好的评估方案。
四、自动化评估工具的开源实践
在 RL/RLHF 场景中,奖励模型(Reward Model, RM)已经成为一种主流自动化评估工具的重要构成,并且出现了专门评估奖励模型的基准,如海外的 RewardBench[1] 和国内高校联合发布的 RM Bench[2],用来测不同 RM 的效果、比较谁能更好地预测人类偏好。下方将介绍 ModelScope 近期开源的奖励模型——RM-Gallery,项目地址:
https://github.com/modelscope/RM-Gallery/
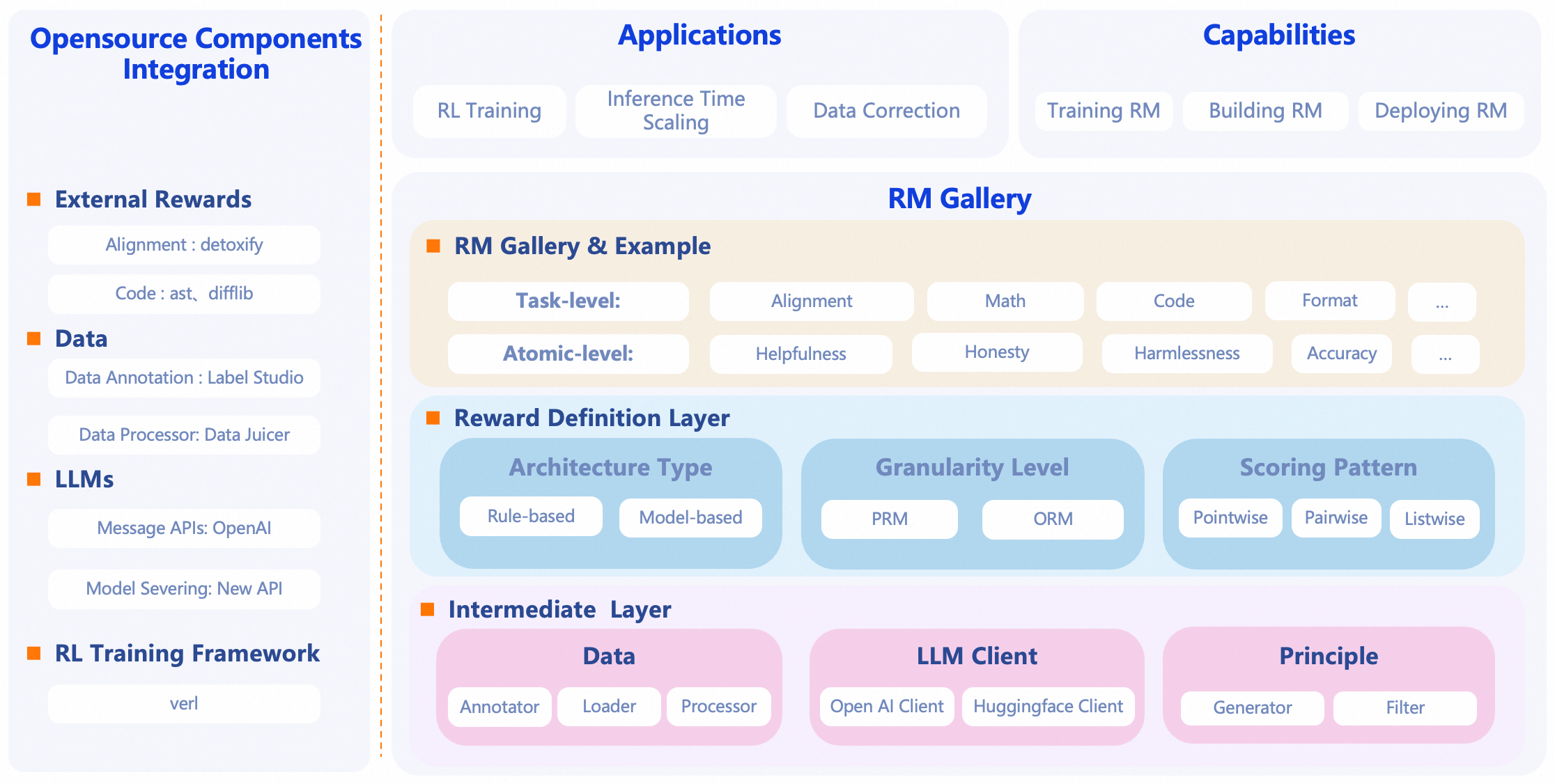
RM-Gallery 是一个集奖励模型训练、构建与应用于一体的一站式平台,支持任务级与原子级奖励模型的高吞吐、容错实现,助力奖励模型全流程落地。
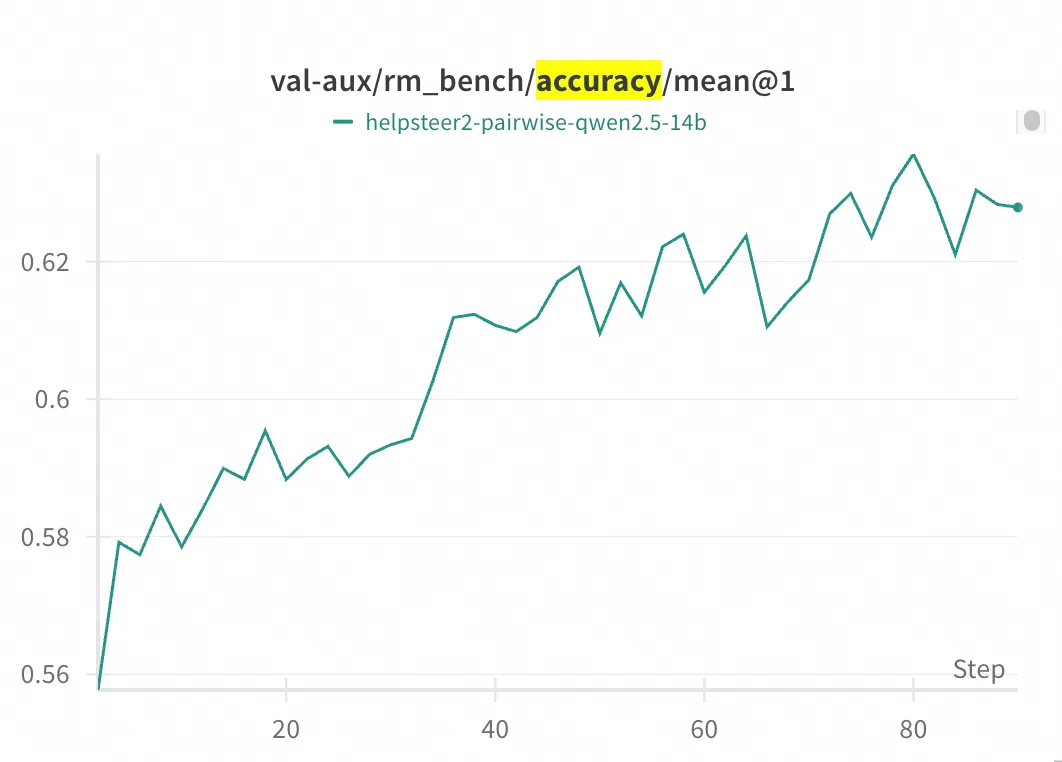
RM-Gallery 提供基于 RL 的推理奖励模型训练框架,兼容主流框架(如 Verl),并提供集成 RM-Gallery 的示例。在 RM Bench 上,经过80步训练,准确率由基线模型(Qwen2.5-14B)的约55.8%提升至约62.5%。
RM-Gallery 的几个关键特性包括:
- 支持任务级别和更细粒度的原子级奖励模型。
- 提供标准化接口、丰富内置模型库(例如数学正确性、代码质量、对齐、安全等)供直接使用或者定制。
- 支持训练流程(使用偏好数据、对比损失、RL 机制等)来提升奖励模型性能。
- 支持将这些奖励模型用于多个应用场景:比如“Best-of-N 选择”“数据修正”“后训练 / RLHF”场景。
所以,从功能来看,它是将奖励模型——即用于衡量大模型输出好坏、优先级、偏好一致性等,打造成一个可训练、可复用、可部署的用于评估工程的基础设施平台。
当然,构建完整的评估工程,仅是一个奖励模型是不够的,还需要设计评估系统的 Level 等级,持续采集业务数据,包括用户对话、反馈、调用日志等,从而进一步优化数据集,训练小尺寸模型、甚至教师模型,形成数据的大小飞轮。有关 AI 评估更详细的内容,可下载《AI 原生应用架构白皮书》,阅读第9章 AI 评估。